-
Settings
What are the requirements for this plugin?
- Redis server 2.8+ - Redis quickstart
- phpredis PHP extension - Install
- Transactions are used and must be supported by the SQL database.
Where can I configure and enable the queue?
In your Matomo (Piwik) instance go to "Settings => Plugin Settings". There is a config section for this plugin.
When will a queued tracking request be processed?
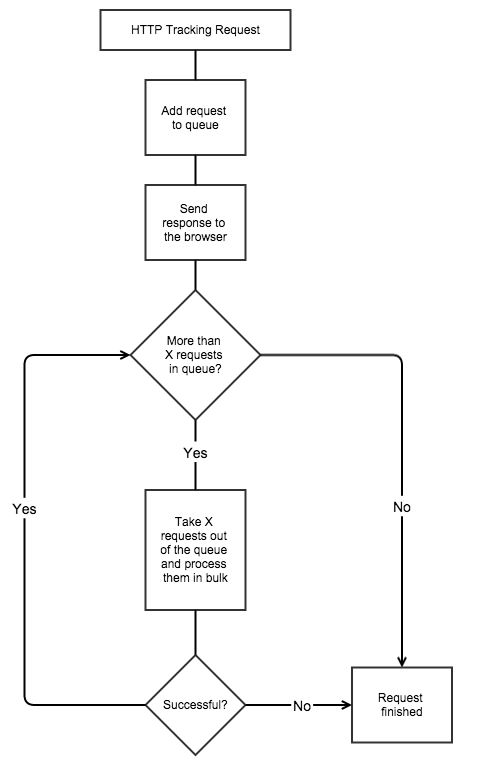
First you should know that multiple tracking requests will be inserted into the database at once using bulk tracking as soon as a configurable number of requests is queued. By default we will check whether enough requests are queued during a regular tracking request and start processing them right after sending a response to the browser to make sure a user won't have to wait until the queue has finished to process all requests. Have a look at this graph to see how it works:
I do not want to process queued requests within a tracking request, what shall I do?
Don't worry, if this solution doesn't work out for you for some reason you can disable it and process all queued requests using the Matomo console. Just follow these steps:
- Disable the setting "Process during tracking request" in the Matomo UI under "Settings => Plugin Settings"
- Setup a cronjob that executes the command
./console queuedtracking:processfor instance every minute - That's it
The queuedtracking:process command will make sure to process all queued tracking requests whenever possible and the
command will exit as soon as there are not enough requests queued anymore. That's why you should setup a cronjob to start
the command every minute as it will just start processing again as soon as there are enough requests. Be aware that it won't
speed up processing queued requests when starting this command multiple times. Only one process will actually replay
queued requests at a time.
Example crontab entry that starts the processor every minute:
* * * * * cd /piwik && ./console queuedtracking:process >/dev/null 2>&1
Can I keep track of the state of the queue?
Yes, you can. Just execute the command ./console queuedtracking:monitor. This will show the current state of the queue.
Can I improve the speed of inserting requests from the Redis queue to the database?
Yes, you can by adding more workers. By default only one worker is activated at a time and only one worker processes tracking requests from Redis to the database. When inserting tracking requests into the database, at time of writing this, about 80% of the time is spent in PHP and the database might be rather bored. If you have multiple CPUs available on your server you can add more workers. You can do this by going in the Matomo Admin interface to "Plugin Settings". There will be a setting "Number of queue workers". Increase this number to the number of CPUs you want to dedeciate for processing requests. Best practice is to add more workers step by step. So first increase this number to 2 and check if the tracking request insertions is fast enough for you. If not and you have more CPUs available, increase the number again.
When using multiple workers it might be worth to lower the number of "Number of requests to process" to eg 15 in "Plugin Settings". By default 25 requests are inserted in one step by using transactions. This means different workers might have to wait for each other. By lowering that number each worker will block the DB for less time.
If you process requests from the command line via ./console queuedtracking:process make sure to always start enough workers. Each time you execute this command one worker will be started. If already enough workers are in process no new worker will be started and the command just finishes immediately.
How fast are the requests inserted from Redis to the Database?
This very much depends on your setup and hardware. With fast CPUs you can achive up to 250req/s with 1 worker, 400req/s with 2 workers and 1500req/s with 8 workers (tested on a AWS c3.x2large instance).
How should the redis server be configured?
Make sure to have enough memory to save all tracking requests in the queue. One tracking request in the queue takes about 2KB, 20.000 tracking requests take about 50MB. All tracking requests of all websites are stored in the same queue. There should be only one Redis server to make sure the data will be replayed in the same order as they were recorded. If you want to configure Redis HA (High Availability) it is possible to use Redis Sentinel see further down. We currently write into the Redis default database by default but you can configure to use a different one.
Why do some tests fail on my local Matomo instance?
Make sure the requirements mentioned above are met and Redis needs to run on 127.0.0.1:6379 with no password for the integration tests to work. It will use the database "15" and the tests may flush all data it contains. Make sure it does not contain any important data.
What if I want to disable the queue?
You might want to disable the queue at some point but there are still some pending requests in the queue. We recommend to
change the "Number of requests to process" in plugin settings to "1" and process all requests using the command
./console queuedtracking:process shortly before disabling the queue and directly afterwards. It is still possible to
process remaining request once the queue is disabled but new tracking requests won't be written into the queue.
How can I access Redis data?
You can either acccess data on the command line via redis-cli or use a Redis monitor like phpRedisAdmin.
In case you are using something like a Redis monitor make sure it is not accessible by everyone.
The processor won't start processing again as it things another processor is processing the data already, what can I do?
First make sure there is actually no processor processing any requests. For example by executing the command
./console queuedtracking:monitor. In case you are using the command line to process tracking requests make sure there
is no processer running using the Linux command ps. If you are sure there is no process running you can release the lock
by executing the command ./console queuedtracking:lock-status. This will output more information which locks are in use and how to unlock them. Afterwards everything should work as normal again.
You should actually never have to do this as a lock automatically expires after a while. It just may take a while depending
on the amount of requests you are importing.
How can I test my Redis / QueuedTracking setup in case I'm getting errors?
There is a command to test some the connection to Redis as well as some needed features: ./console queuedtracking:test.
It might directly give you an error message if something goes wrong that helps you to resolve the issue. If your queue
is always locked you might be as well interested in executing .console queuedtracking:lock-status.
How can I debug in case something goes wrong?
- Use the command
./console queuedtracking:monitorto view the current state of all workers - Use the command
./console queuedtracking:lock-statusto view the current state of all locks - Set the option
-vvvwhen processing via./console queuedtracking:process -vvvto enable the tracker debug mode for this run. This will print detailed information to screen. - Enable tracker mode in
config.ini.phpvia[Tracker] debug=1if processing requests during tracking is enabled. - Use the command
./console queuedtracking:print-queued-requeststo view the next requests to process in each queue. If you execute this command twice within 1-10 minutes, and it outputs the same, the queue is not being processed most likely indicating a problem.
I am using the Log Importer in combination with Queued Tracking, is there something to consider?
Yes, we recommend to set the "Number of requests to process" to 1 as the log importer usually sends multiple requests at once using bulk tracking already.
How can I configure the QueuedTracking plugin to use Redis Sentinel?
You can enable the Sentinel in the plugin settings. Make sure to specify the correct Sentinel "master" name.
When using Sentinel, the phpredis extension is not needed as it uses a PHP class to connect to your Redis. Please note that calls to Redis might be a little bit slower.
Can I configure multiple Sentinel servers?
Yes, once Sentinel is enabled you can configure multiple servers by specifying multiple hosts and ports comma separated via the UI.
Are there any known issues?
- In case you are using bulk tracking the bulk tracking response varies compared to the regular one. We will always return
either an image or a 204 HTTP response code in case the parameter
send_image=0is sent. - Anything related with Cookies won't work
- By design this plugin can delay the insertion of tracking requests causing real time plugins to not show the actual data since under load tracking requests may take a while until they are replayed.
View and download this plugin for a specific Matomo version: